New! … Well, 16 years late. A short indie horror film which I co-produced, acted in, and compsosed the music for, back in 2005. Stream it now …
Free gift for lovers of apocalyptic fiction in the vein of John Wyndham (The Day of the Triffids) and John Christopher (The Death of Grass) …


Back in 2007, my sci-fi doomsday novel Chion had a good run in paperback, also gaining an award as book of the year on a review site. It’s no longer in print, so I’ve decided to resurrect it as an ebook. And there’s no better price than free!
Kindle users should download the MOBI version and copy it into the ‘documents’ folder on their device. Kobo users should download the EPUB version. If any readers wish to express their enjoyment of the story by making a small donation, that will make my day. No pressure.

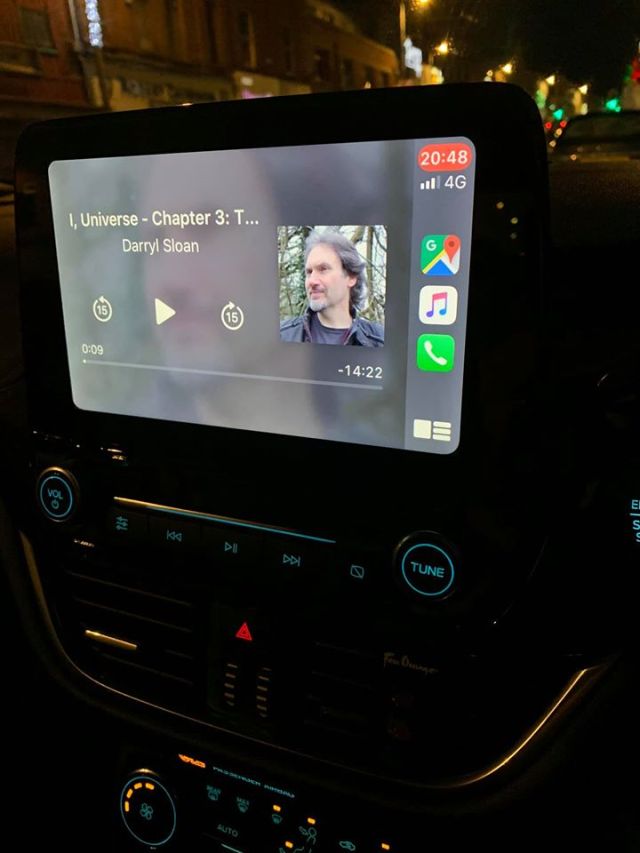
Attention audiophiles! I, Universe hits the soundwaves …
 Whether you’re out for a walk, driving the car, commuting to work, or merely doing the dishes, audiobooks are a great way to pass the time. I, Universe is now available for your listening pleasure, spanning over 14 hours.
Whether you’re out for a walk, driving the car, commuting to work, or merely doing the dishes, audiobooks are a great way to pass the time. I, Universe is now available for your listening pleasure, spanning over 14 hours.
It’s instantly available to download for anyone who cares to join me on Patreon, where I’m much more active these days than on YouTube. All you have to do is sign up with a minimum $1 monthly pledge (which you can discontinue at any time).
Alternatively, you can buy the audiobook as a digital download for a one-off payment of £5.00 (currency conversion from $ will be handled automatically).